Large Language Models
00 Temp
Responsible AI
- mitigate potential biases
- toxicity - LLM returns responses that can be potentially hrmful or discriminatory towards protected groups or towards attributes ← diverse set of annotators
- hallucinations - things that seem true but are not or have no basis for it, generates factually incorrect content ← educate users how Generative AI works, add disclaimers, augment LLMs with independent, verifiable databases
- define intended/unintended use cases
- intellectual property, ensure people aren’t plagiarizing, make sure there aren’t any copyright ← filtering and blocking approaches
- responsibility
- define use cases: the more specific/narrow, the better
- assess risk for each use case
- evaluate performance for each use case
- iterate over entire AI
- governance policy for all stakeholders
On-going research
- responsible AI
- scale models and predict performance
- more efficiencies across model development lifecycles COnstitutional AI
Generative AI Project Lifecycle Cheat Sheet
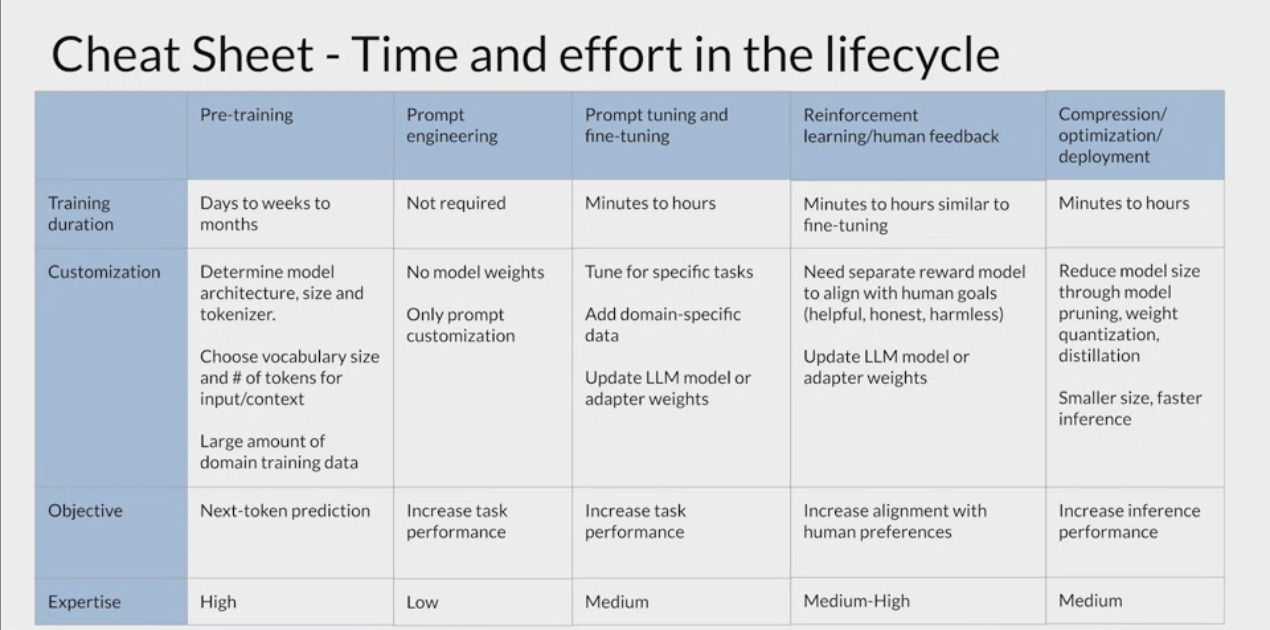 Generative AI Project Lifecycle by Coursera Generative AI Course
Generative AI Project Lifecycle by Coursera Generative AI Course
01 Background
Resources
🔧 Tools
- HuggingFace
- Langchain
- ChatGPT
- Llama
What powers Large Language Models (LLMs)?
02 Important Concepts
Prompt Engineering
Prompt is the text that is feed into the model. Prompt Engineering is … to get the model to behave the way you want.
Different types of prompting methods
- Chain of Thought (CoT) Wei et al. 2022
- Program-Aided Language Models Luyu Gao. 2022
- Tree of Thoughts (ToT) Shunyu Yao, 2023
- GoT (Graph of Thoughts) Besta et al. 2023
Different types of feedback.
- ReACT source 1
In-Context Learning Providing examples (of the task that you want the model to carry out) in the context window.
- Zero-shot Inference:
- One-shot Inference: Inclusion of a single example.
- Few-shot Inference:
Key Terms
- Few-shot Exemplars: Few-shot exemplars are small sets of examples or data points to guide or instruct the model. The term “few-shot” indicates only a limited number of example are used. Multi-Shot would involve multiple examples.
- Context Window: The full amount of text or memory available to use for prompt.
- Instruction Fine-Tuning
- Full-Fine Tuning
- Parameter Efficient Fine-Tuning
- Reinforcement Learning Human Feedback
- Reasoning Traces
- Thought Trajectories
- Task Solving Trajectories
- Question-Answer (QA) System:
- Multi-hop Question-Answering: Requires a model to retrieve and integrate information from multiple passages to answer a question.
Metrics
- Exact Match (EM): For each question + answer pair, if the characters of the model’s prediction exactly match the character of (one of) the True Answers, EM = 1, otherwise EM = 0. This is a strict all or nothing metric; being off by a single character results in a score of 0. source
Generative Configuration (inference parameters)
- max new tokens
- sample top k
- sample top p
- temperature: scaling factor that is applied within the final softmax layer of the model that impacts the shape of the probability distribution of the next token, influencing the predictions that the model will make. A lower temperature results in a probability distribution from the softmax is more strongly peaked, with the probability being concentrated in a smaller number of words (less random less).

Hot Terms
What is Auto-GPT? What is Baby-GPT? What is LocalAI? What is RAG? Retrieval Augmented Generation Help LLMs be more accurate and up to date.
Let’s first explain the “Generation” part. Imagine this: Your child asks you, “In our solar system, which planet has the most moons?“. You answer: “Oh, that’s really great that you’re asking this question. I loved space when I was your age”. Then you think, I read an article a while ago that said it was Jupiter and 88 moons. So you say. “The answer is Jupiter with 88 moons”.
However, there are two problems with this answer.
- No source: although you read an article and are confident about the answer, you are essentially giving the answer off the top of your head.
- Hallucination: the article was read a while ago, the answer is out of date.
These are two challenges that a LLM (without RAG) would also face. “Retrieval-Augmented” portion, instead of just relying on what the LLM knows (what it has been trained on), we add a context store (web, documents, etc). The LLM attempts to talk to the context store to retrieve information that is relevant to what the user’s query was.
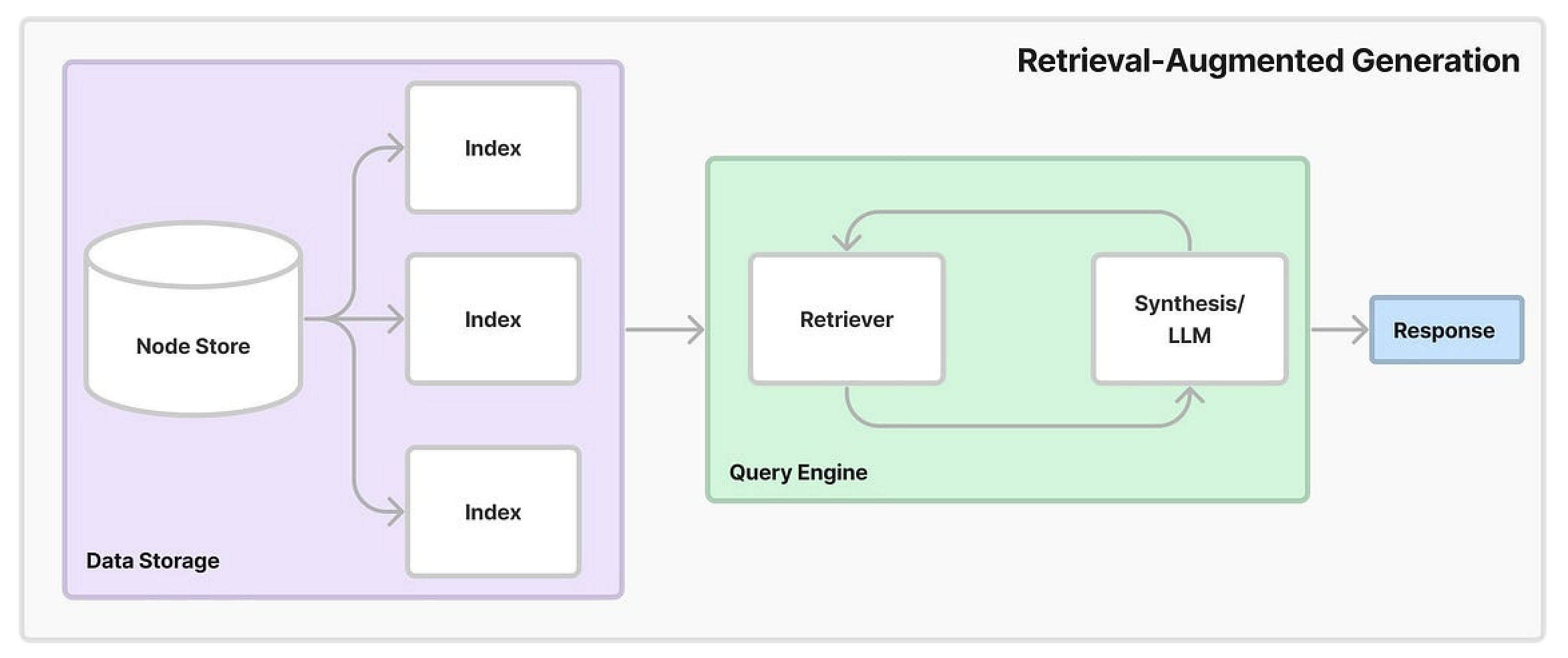
For example, what if you instead first looked up answers from a reputable source such as NASA. Then you could update your answer: “The answer is Saturn with 146 moons”. The RAG system aims to first retrieve information from a source, solving the first problem, and combine it with the given prompt, and produce an answer. Augmenting the context store with up-to-date information would solve the second problem.
02 Training LLMs
Here is a good overview of the LLM creation pipeline.
Select: choose an existing model or pre-train your own
- LLM pre-training phases aims at encoding the model with a “deep representation of language”. Learns from vast amounts of unstructured textual data (GB-TB-PB sizes). This is a self-supervised learning step.
- Training a LLM is computationally expensive, with parameter + overhead often exceeding memory limit. Can be solved with (1) quantization (2)
- Pre-training for domain adaptation.
Computation petaFLOP per second day: measure the number of floating-point operations performed at a rate of one petaFLOP per second, running for a full day.
GPU Training
- Distributed Data Parallel (DDP)
- Fully Sharded Data Parallel (FSDP) motivated by Zero Redundancy Optimizer (ZeRO) paper.
03 Fine-Tuning
Prompt engineering has its limitations:
- In context learning doesn’t work for smaller models
- Examples take up space in the context window
- Model doesn’t necessarily improve by adding more and more examples Fine-tuning of large model is another method to change the behavior to be more helpful (accomplish the task you need it to do).In contrast to pre-training, fine-tuning uses supervised learning process. Datasets labels are prompt-completion pairs (with dataset size of GB-TB), helping the model to generate good completions for a specific tine.
Instruction Fine-Tuning
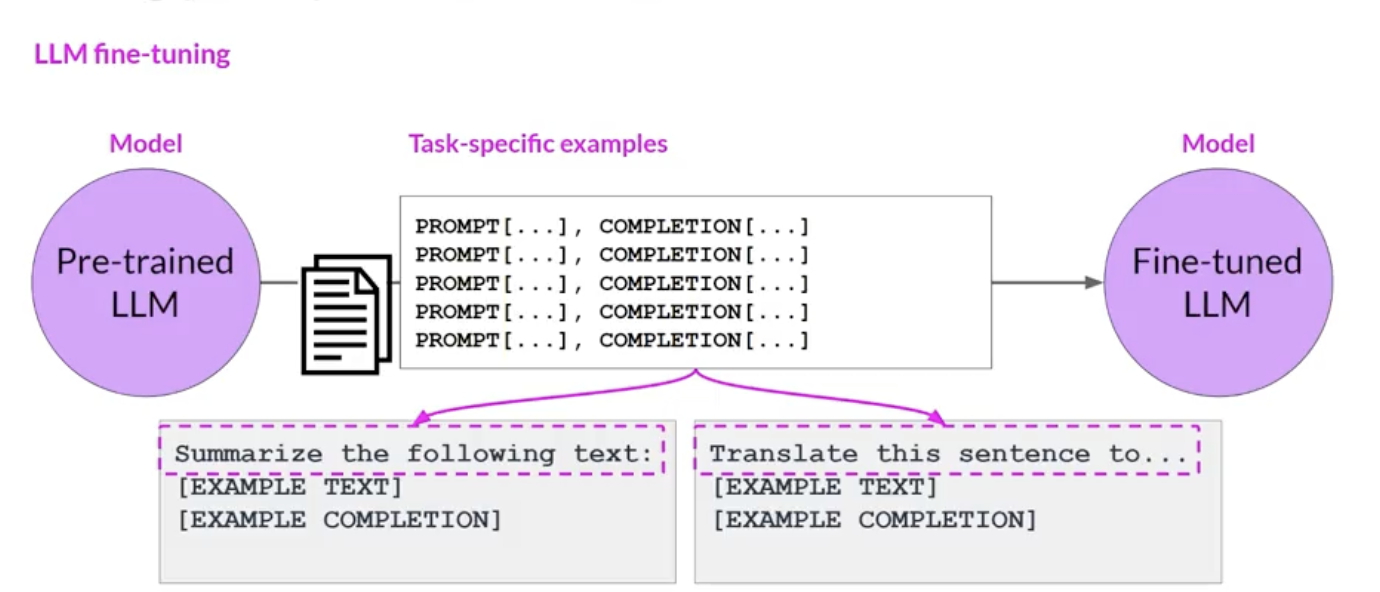
- Full fine-tuning, all model’s weights are updated (high compute budget)
Tip
Fine-tuned LLMs are also known as Instruct LLM. The process is known as fine-tuning, full fine-tuning, or instruction fine-tuning.
- single vs multi-task instruction fine tuning
Examples - FLAN (Fine-tuned LAnguage Net) models refer to a specific set of instructions used to perform instruction fine tuning. FLAN-T5 is the FLAN instruction version of the T5 foundation model. It is a good general purpose, instruct model introduced in [Chung et al. 2022, Scaling Instruction-Finetuned Language Models]
Parameter efficient fine-tuning (PEFT)
Alternative to full instruction fine-tuning, PEFT “preserves (majority of or all of) the weights of the original LLM and trains only a small number of task-specific adapter layers and parameters”. This is much more realizable when compute budget is constrained, resulting in a much smaller footprint (perhaps only several megabytes) and can be done on a single GPU. The new parameters are then combined with the original LLM weights for inference and can be easily swapped out for inference. This is in contrast to full fine-tuning, which creates a full copy of the original LLM for each task.
Methods
- Selective - select subset of initial LLM parameters to fine-tune
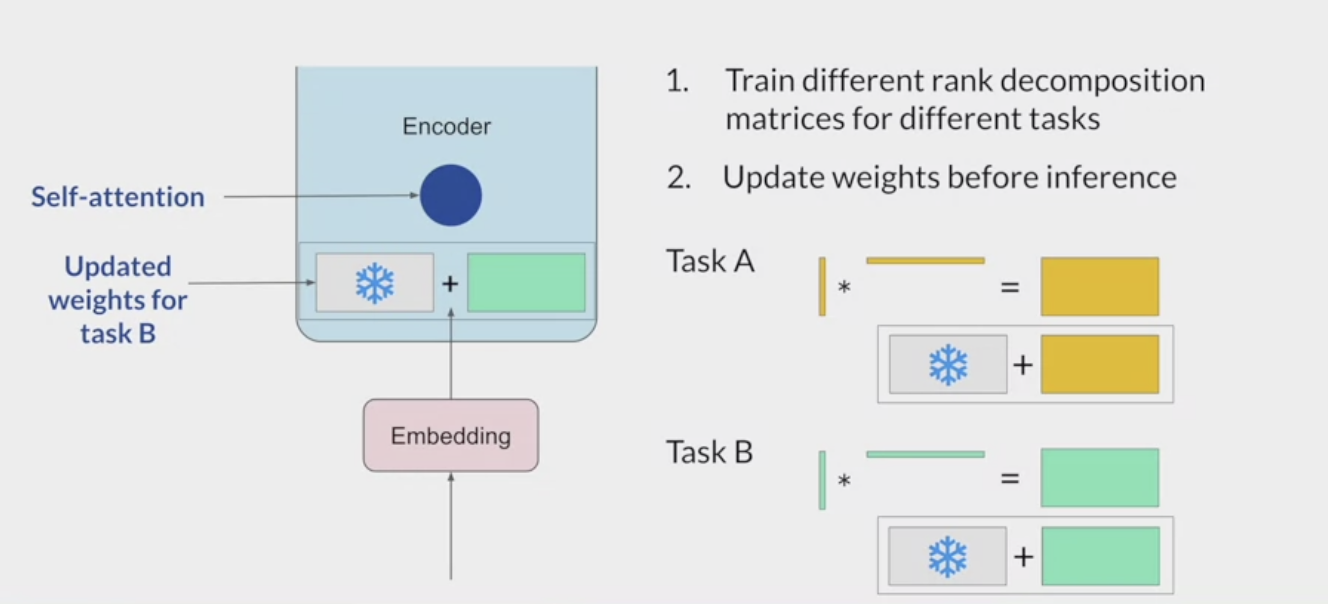
- Reparameterization - reparameterize model weights using a low-rank representation (creating new low rank). Ex. LoRA.
- Additive - keep original model parameter frozen, add new parameters
- adapters - add new trainble layers to the architecture of the model, typicall inside the encoder or decoder components
- soft prompts - keep the model architecture fixed and frozen, focus on manipulating the input to achieve better embeddings or keep the input fixed and retraining the embedding weights.
Trade-offs
- Parameter efficiency
- Training speed
- Inference costs
- Memory efficiency
- Model performance
Low-rank Adaptation (LoRA)
Hu et al. 2021. LoRA: Low-Rank Adaptation of Large Language Models
Training Process
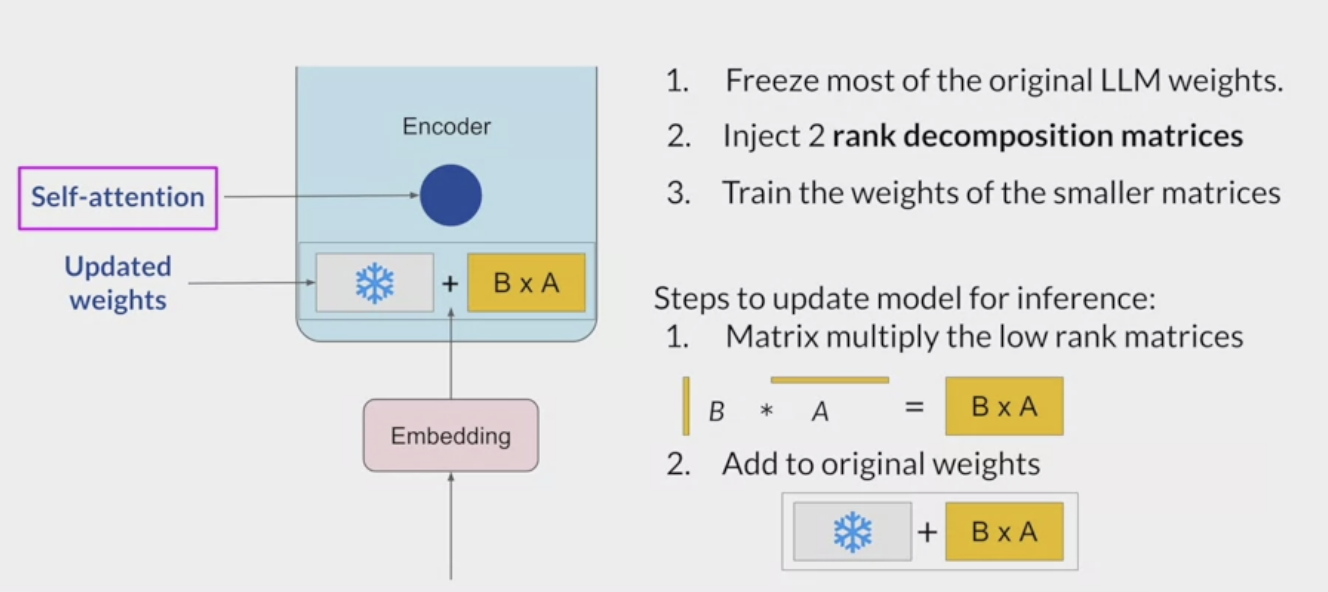 Inference Process
Inference Process
Prompt Tuning
Lester et al. 2021. The Power of Scale for Parameter-Efficient Prompt Tuning
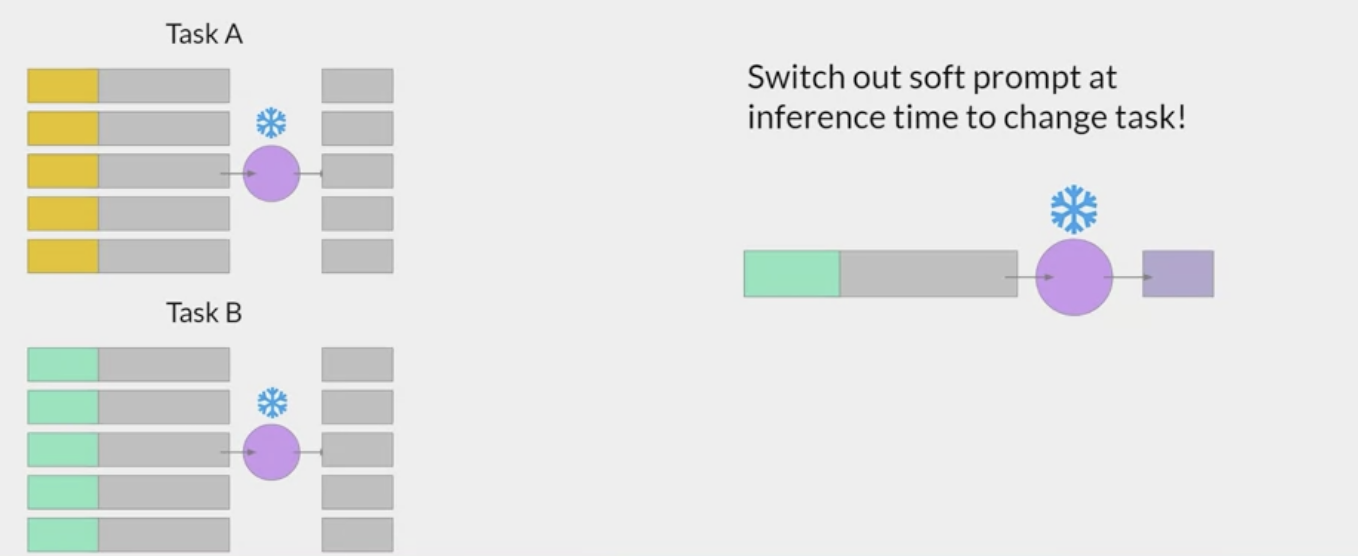
A type of soft-prompts.
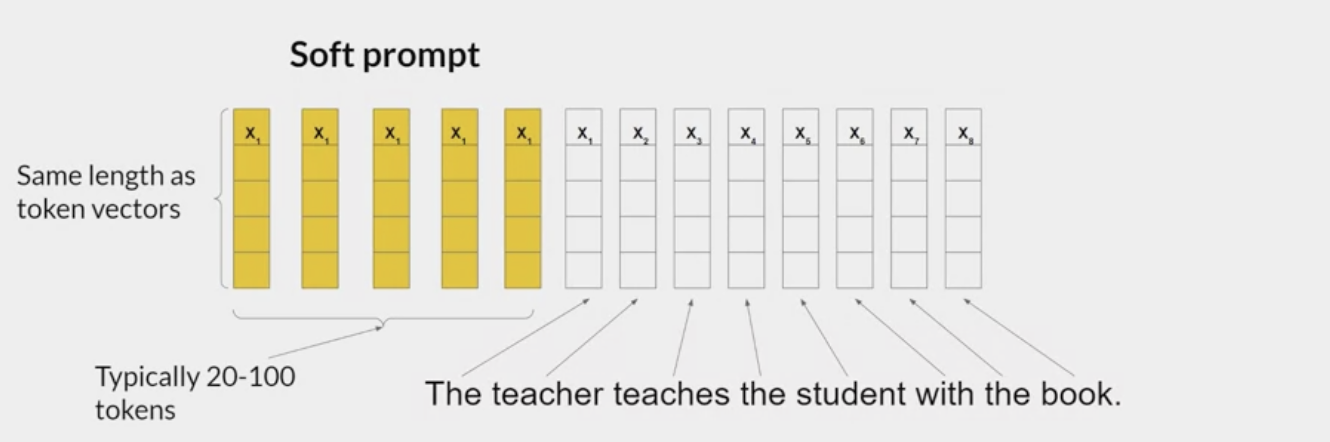
set of trainable tokens gets prepended to embedding vectors that represent your input text. the soft prompt vectors have the same length as the embedding vectors of the language tokens.
04 Reinforcement Learning with Human Feedback
Align the model with human values / human feedback, helpful, honest, harmless HHH.
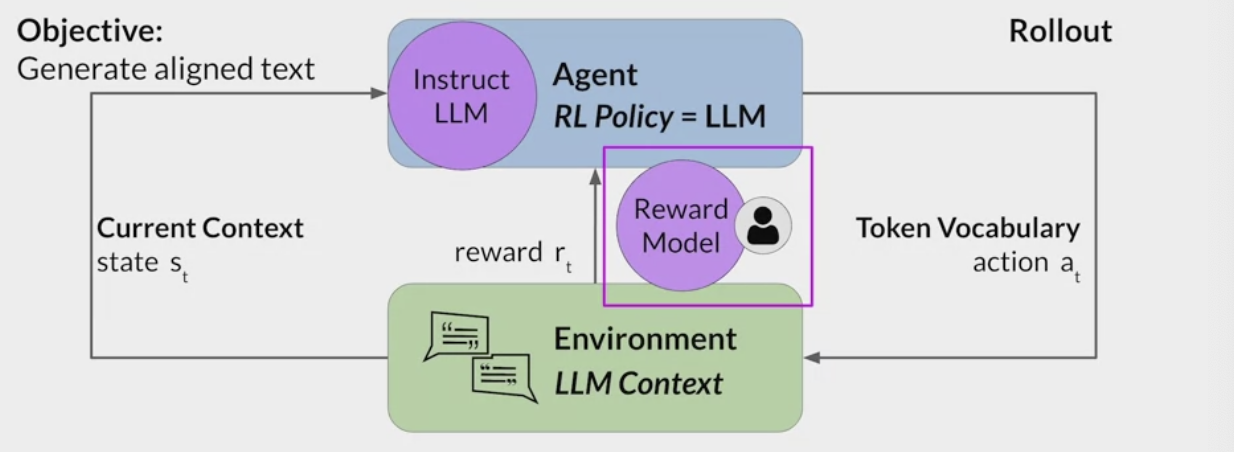 The reward model is the central component of the reinforcement learning process. It encodes all of the preferences that have been learned from human feedback, and it plays a central role in how the model updates its weights over many iterations.
The reward model is the central component of the reinforcement learning process. It encodes all of the preferences that have been learned from human feedback, and it plays a central role in how the model updates its weights over many iterations.
Process.
- Define your model alignment criterion.
- For the prompt-response sets that you just generated, obtain human feedback through labeler workforce. Need a criterion helpfulness. This gets repeated for many prompts with many different labelers with diverse and global thinking.
Using the reward model and RL algorithm to fine-tune LLM
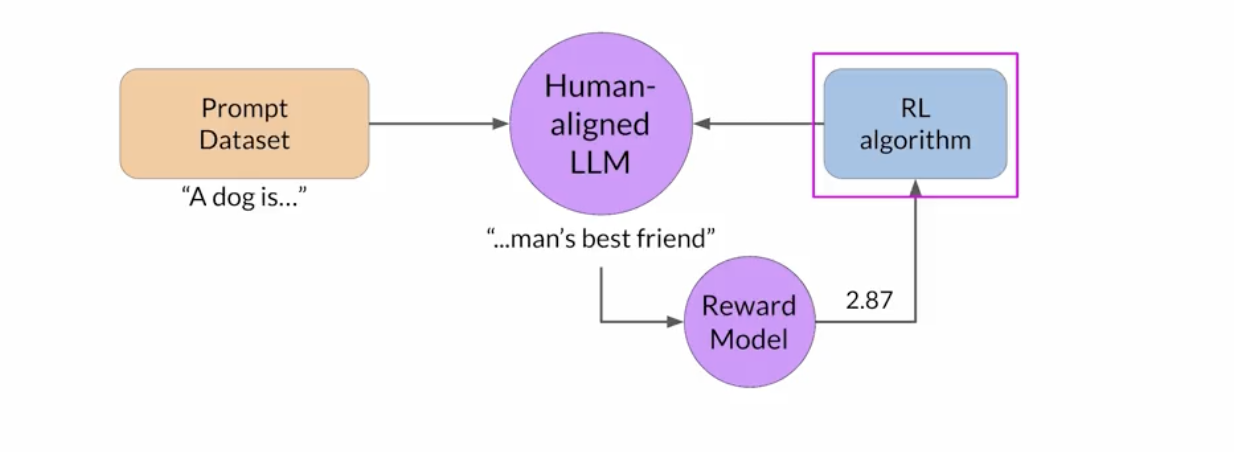 With each response of the RLHF, the goal is to have the reward model give higher rewards until a predefined threshold.
With each response of the RLHF, the goal is to have the reward model give higher rewards until a predefined threshold.
So what are these RL algorithms?
- PPO
PPO Proximal Policy Optimization
Reward Hacking When the model starts generating outputs that simply maximize the reward from the reward model, even if the output isn’t optimal.
One method to avoid reward hacking is to have a reference model (sometimes the base Instruct Model) to compare the response from the RL-updated LLM, calculated the KL Divergence Shift Penalty, a statistical measure to measure how different two density distributions are. This penalty is added to the reward model.
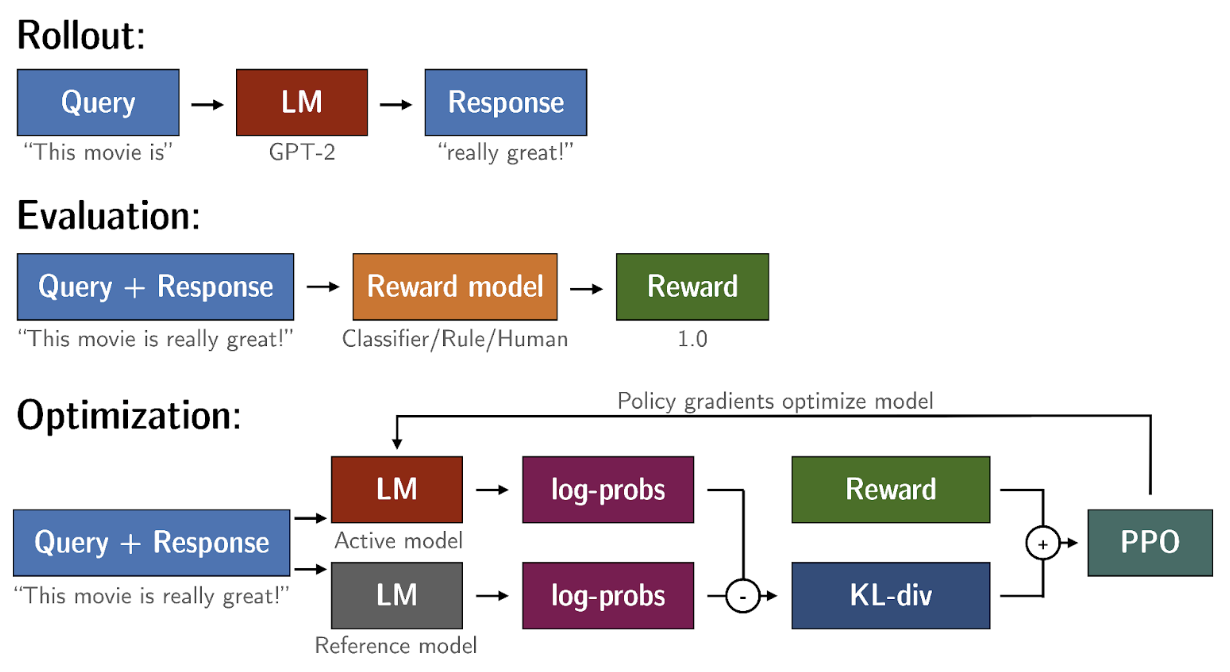 Scaling Human Feedback
The human effort required to produce the trained reward model in the first place is huge. As the number of models and use cases increases, human effort becomes a limited resource.
Scaling Human Feedback
The human effort required to produce the trained reward model in the first place is huge. As the number of models and use cases increases, human effort becomes a limited resource.
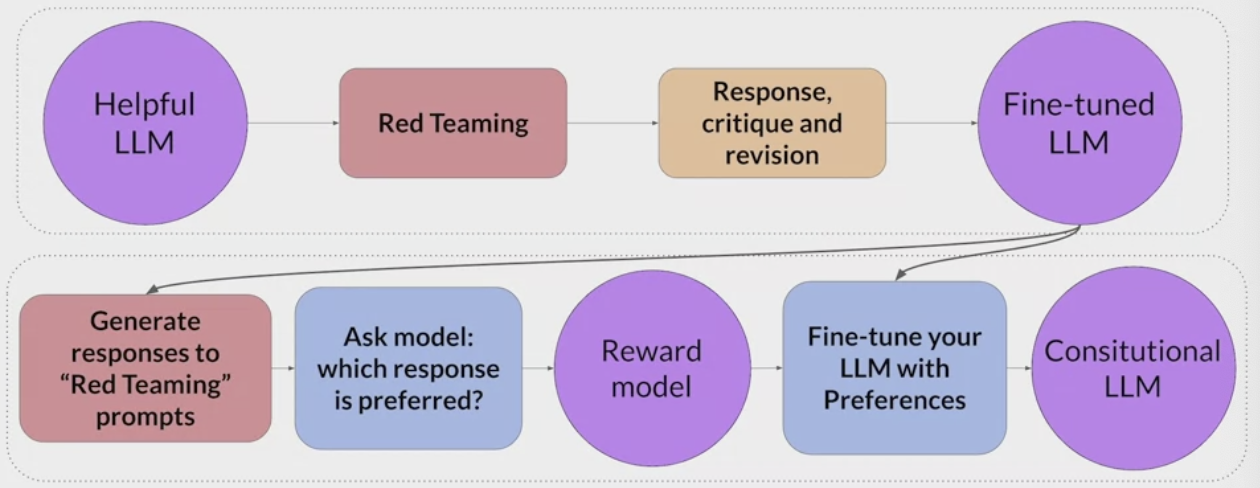
Thus, methods to scale human feedback are an active area of research. One idea to overcome these limitations is to scale through model self-supervision.
Constitutional AI is one method of self supervision. Trains models using a set of rules and principles that govern the model’s behavior.
Train the model to self critique and revise it’s response to those examples.
03 Evaluating LLMs
How to compare performance of pre-trained and tuned models. (2023) A Survey on Evaluation of Large Language Models https://arxiv.org/abs/2307.03109 (2023) Evaluating Large Language Models: A Comprehensive Survey https://arxiv.org/abs/2310.19736
Datasets
- Summaration
- SAMSum
- DialogSum
Metrics
- Recall Oriented Under Study for Jesting Evaluation (ROUGE): used for text summarization (compares a summary to one or more reference summaries)
- ROUGE-1: only use unigram
- Precision:
- F1:
- ROUGE-2: only use bigram
- ROUGE-n: use n-gram
- ROUGE-L: use of longest common subsequence
- ROUGE Clipping
- ROUGE-1: only use unigram
- Bilingual Evaluation Under Study (BLEU): average precision over a range of n-gram scores for text translation
Evaluations Benchmarks
- GLUE (General Language Understanding Benchmark) introduced in [Wang et al. 2018. GLue: A Mult-Task Benchmark and Analysis Platform for Neural Language Understanding]
- SuperGLUE introduced in [Wang et al., 2019, SuperGLUE: A Sticker Benchmark for General-Purpose Language Understanding Systems]
- MMLU (Massive Multitask Language Understanding) introduced in [Hendrycks. 2021. Measuring Massive Multitask Language Understanding]
- BBH (Big Bench Hard) introduced in [Suzgun et al., 2022, Challenging BIG-Bench tasks and whether chain-of-thought can solve them]
- HELM (Holistic Evaluation of Language Models)
- Metrics for (1) Accuracy (2) Calibration (3) Robustness (4) Fairness (5) Bias (6) Toxicity (7) Efficiency
03 Sentinel Papers
(2019) Scaling Laws for Neural language Models (2020) Learning to summarize from human feedback (2020) Language Models are Few-Shot Model (2020) Laura… (2020) Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks (2022) Training Compute Optimal Large Language Models (2022) Chain of Thought (2022) Constitutional AI: Harmlessness from AI Feedback (2023) LLaMA: Open and Efficient Foundation Language Models (2023) BloombergGPT: A Large Language Model for Finance (2024)
05 LLM-Powered Applications
Model Optimizations
How to improve inference speed without reducing model performance? #TODO More details about model optimization methods
Distillation Where a larger “teacher” model trains smaller “student” model. The student model learns to statistically mimic the behavior of the teacher model, either in just prediction layer or hidden layer. Goal is to minimize distillation loss. Better for generative encoder models… The smaller model is used for inference.
Quantization QAT, Quantization Aware Training, PTQ Post-Training Quantization, can be applied to model weights (And/or ativation), requires callibraton to capture dynamic range (reduces performance, but perhaps at a good improvement)
Pruning Remove model weights with values close or equal to zero 1. Full model re-training 2. PEFT/LoRA 3. Post-training
optimizing and deploy model for inference (how fast, compute budget, inference speed vs storage) additional resources? how will it connect to those resources. how will model be consumed?
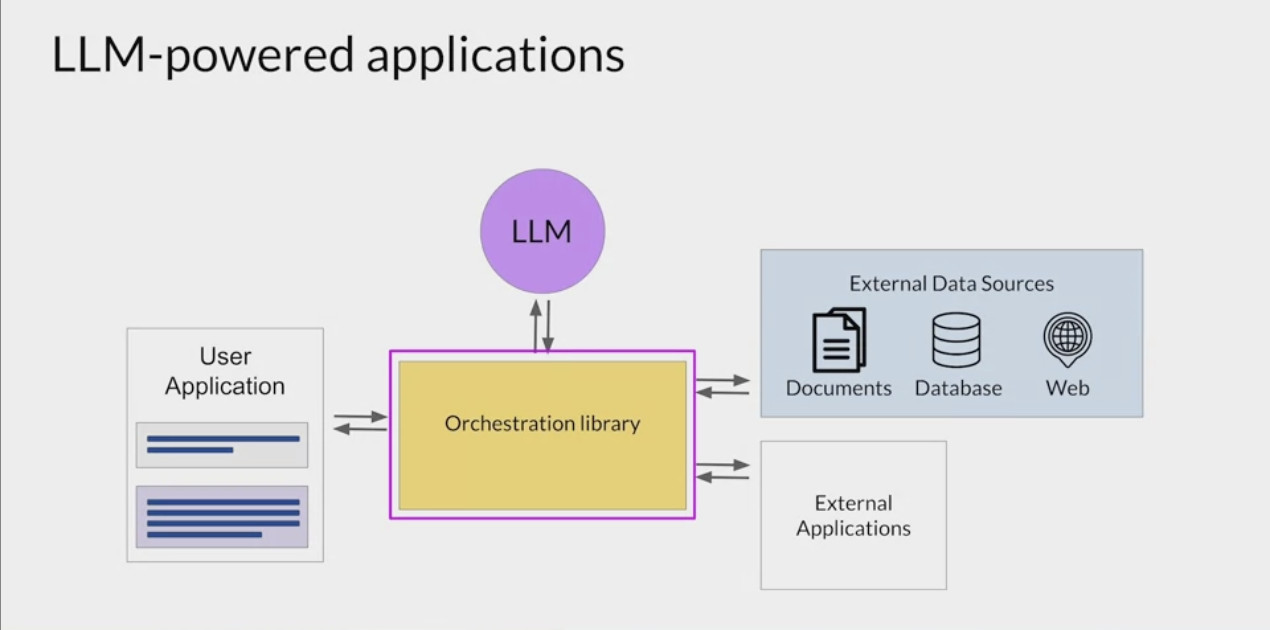 Orchestration library
Orchestration library
- connect LLM to outside data sources, give access to data it did not previously see in training ← RAG!,
- connect LLM to outside interpertors…
- orchestration library examples are Langchain
Architecture
