Generative Adversarial Networks
01 Background
Generative Adversarial Networks are widely applied in vision tasks, such as Image Synthesis, Video In-painting, and Visual Style Transfer. A typical image-generation GAN contains a generator network (G) and a discriminator network (D). G is trained to generate fake images that can fool D, while D aims to distinguish the real images and synthetic images. For example, image synthesis can be shown below.

The following formula can be used to describe the process. It is also called the adversarial loss.
where
- are real training samples
- are the random noise samples.
- is the generated images using the neural network generator
- is the output of the discriminator, which specifies the probability of the input being real.
In order to understand this formula, note that the discriminator is simply a classifier that performs a binary classification. Recall the equation of a Binary cross-entropy loss function. This implies that should be 1 when as it is fed real training data from and the output of as 0. Calculating the the loss using the binary cross-entropy loss function for both these cases we get the following values. L(D(x), 1) = \log{D(x)}, \space L(D(G(Z), 0)) = \log{(1-D(G(Z)))} \tag{1} Remember the goal of the discriminator is to maximize the the loss functions, or become better at discriminating between real and fake samples. This gives us the inner portion of the formula above.
If we want the max loss function for the discriminator over a batch of samples, we arrive with the expected notation.
The generator, on the other hands, needs to trick the discriminator by generating images that are as real as possible. This means that generated images should pass though the discriminator and be labeled as 1. In other words, it wants to minimize the chance of an image being fake (0). Looking at the formula, we want to minimize
Or for a batch.
Not that the generator is never fed real images, thus we can ignore the first term when putting (2) and (3) together to get (1)
To summarize, this means that the discriminator parameters (Defined by D) will maximize the loss function and the generator parameters will minimize the loss function.
It is important to note that the generator and discriminator are not trained simultaneously, but one at a time, i.e freeze the other network
This article on Medium is a good review on understanding the intuition behind GANs, the random noise vector , and the formula described above.
02 Concepts
- There are two main directions to modify a GAN
- loss function
- network backbone
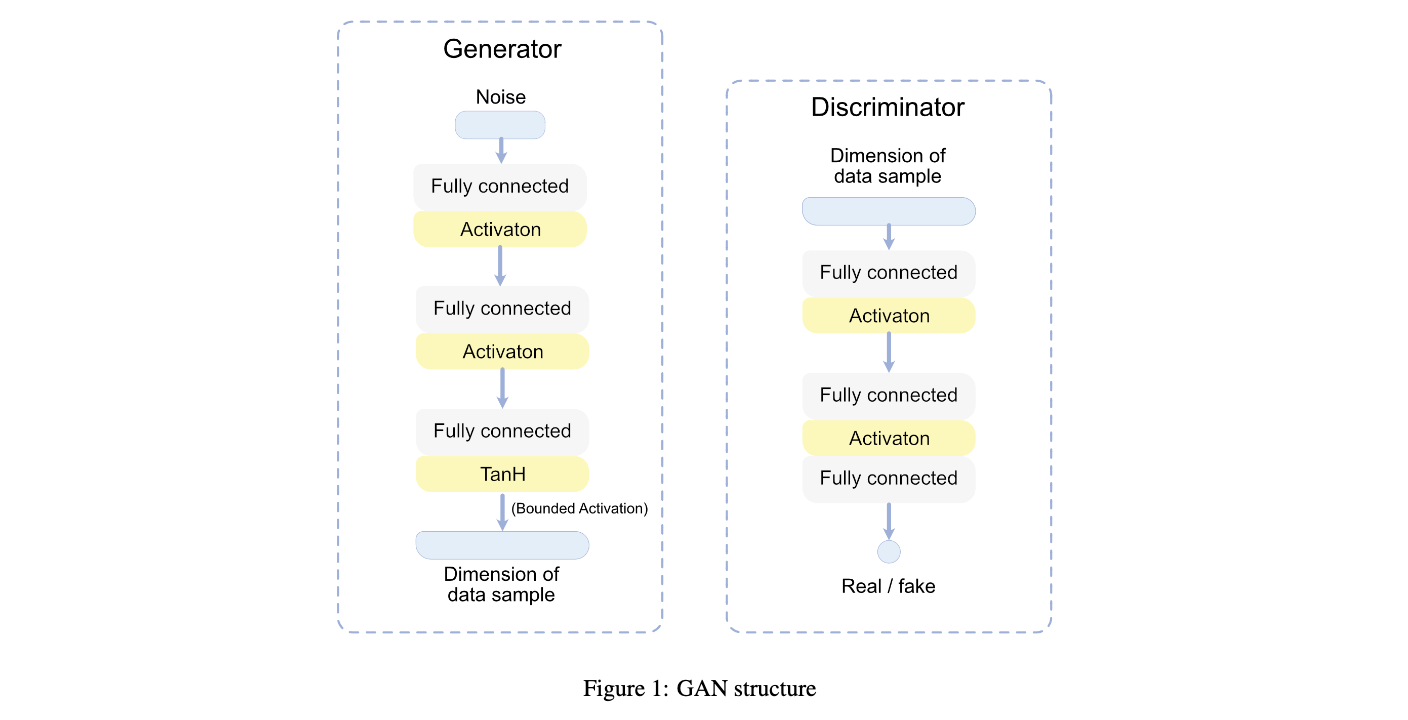
03 Famous GAN Developments
GAN (2014)
Background
Paper: Ian J. Goodfellow et. al., 2014, Generative Adversarial Networks Resources
- https://medium.com/analytics-vidhya/understanding-gans-deriving-the-adversarial-loss-from-scratch-ccd8b683d7e2 💡 Paper that first outlined the concept of GAN.
CGANS (2014)
Background
Paper: Mehdi Mirza and Simon Osindero, 2014, Conditional Generative Adversarial Nets
DCGANS (2015)
3DGANS (2016)
Paper: Learning a Probabilistic Latent Space of Object Shapes via 3D Generative-Adversarial Modeling