Statistics
- 00 Background
- 01 Probability
- [[#01 Probability#01.01 Sets|01.01 Sets]]
- [[#01 Probability#01.02 Probability|01.02 Probability]]
- [[#01 Probability#01.03 Distributions|01.03 Distributions]]
- 02 Random Variables
00 Background
Books
TODO Statistically significant?
Roadmap
- MLE, MAP, Maximum Likelihood Loss
00 Other Maths
- Summations Formulas: Taylor Series,
01 Sets
Understanding basic set theory can give us a better intuition in probability. Definition: Complement Definition: Subset Definition: Union Definition: Intersection Definition: Disjoint
02 Probability
After reviewing what a random variable is, we will discuss the basic properties: probability density function, probability mass function, expectation, variance, covariance, correlation for a single random variable. Next we will expand this to fit random variable vectors or multivariate random variables, while denoting the difference between continuous and discrete random variables.
02.01 Random Variable
Before we begin, let’s review what a random variable is. A random variable is simply a function that maps outcomes in a sample space (random process) to a measurable space (or range) . In other words, the set Let’s take the example of flipping a fair coin once. Let be the sample space and let be the measurable space . A random variable can be defined as a function X = \cases{1 & if Heads \\ -1 & if Tails}, \space \text{or} \space X(T)=1, X(H) = -1 The above random variable is known as a discrete variable, this is because the random variable can only assume a countable set of values, in this case, . The other type is continuous, where a random variable can assume any value across a continuum (range). An example of continuous: Let be the sample space all possible heights. A random variable may map all possible heights into a subset of heights, perhaps for a specific population, such as the “range of heights of asians of ages 10-20”. The range therefore is also continuous.
Remark: In some cases, it might be difficult to define the sample space of a continuous random variable. Instead, we focus on the range . Read more here
02.02 Probability and Distributions
In probability and statistics, given a random variable , its range becomes the sample space of interest. It is often used to model a probabilistic outcome, also known as distribution. For example, following discrete example above, we can ask, what is the probability that , denoted . In this simple example, we know this value is . The distribution would represented the probabilities of each value in the . . Let’s discuss a slightly more difficult example.
Example: Let represent the sum of two fair dice. The sample space is . The probability for each role . The random variable . The possible outcomes and its probabilities are:
| X | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| P(X) | 1/36 | 2/36 | 3/36 | 4/36 | 5/36 | 6/36 | 5/36 | 4/36 | 3/36 | 2/36 | 1/36 |
is the probability distribution. It can be graphed as.
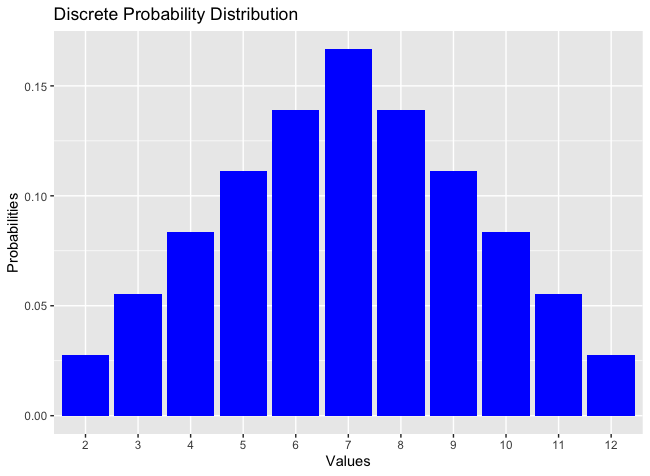 The probability for defines a function that gives the probability of each individual element on the range . This function (for a discrete random variable) is called the probability mass function or pmf of . The induced probability distribution of is then defined as P_{X}(D) = \sum\limits_{d_{i\in}D}p_{X}(d_{i}), D\subset \mathcal{D} \tag{1} In the graph, each individual bar is while the entire distribution is .
The probability for defines a function that gives the probability of each individual element on the range . This function (for a discrete random variable) is called the probability mass function or pmf of . The induced probability distribution of is then defined as P_{X}(D) = \sum\limits_{d_{i\in}D}p_{X}(d_{i}), D\subset \mathcal{D} \tag{1} In the graph, each individual bar is while the entire distribution is .
Example: Now let’s look at a continuous case. Let’s say the weight of an adult is modeled by a continuous random variable . Unlike before, where we are interested of the probability of a discrete value, such as , we may instead be interested in the probability of a range of values. For example, the probability that an adult person weights over 200 pounds (while the average is 185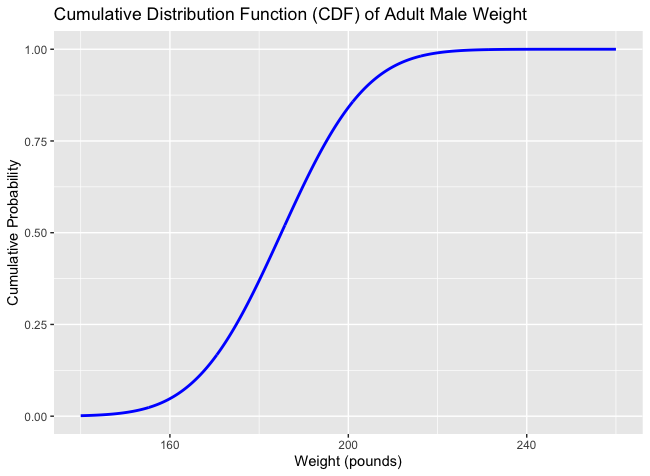 . The function of can be represented as a normal distribution, which will be talked about later.
. The function of can be represented as a normal distribution, which will be talked about later. 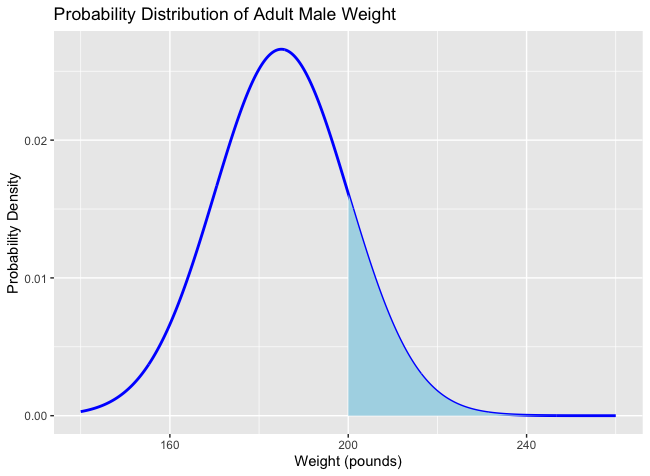 The function of continuous random variable is denoted as and called the probability density function or pdf. The induced probability distribution of the the pdf is denoted as
P_{X}[(a,b)]=P[\{c\in\mathcal{C}: a<X(C)<b\}] = \int^{b}_{a}f_{X}(x)dx \tag{2}
Thus, distributions of a continuous random variable is denoted by .
The function of continuous random variable is denoted as and called the probability density function or pdf. The induced probability distribution of the the pdf is denoted as
P_{X}[(a,b)]=P[\{c\in\mathcal{C}: a<X(C)<b\}] = \int^{b}_{a}f_{X}(x)dx \tag{2}
Thus, distributions of a continuous random variable is denoted by .
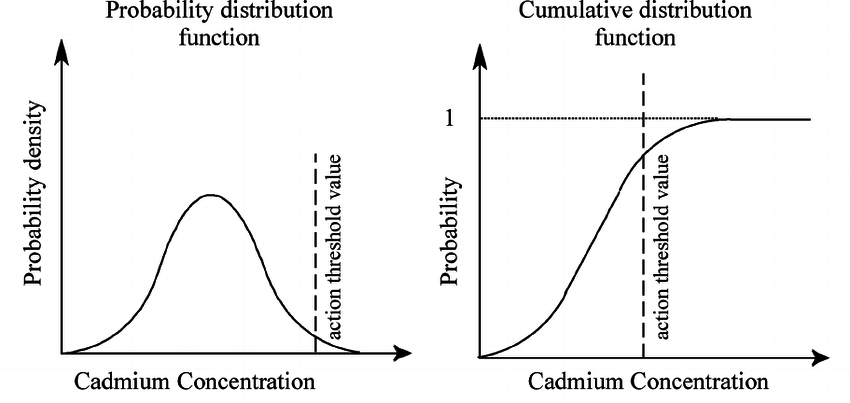
Cumulative Distribution Function CDF: Let be a random variable. Then it’s cumulative distribution function is defined by , where Examples: If we take the previous two examples, we graph out the CDF’s of both discrete and continuous random variable.
| CDF for Discrete | CDF for Continuous |
|---|---|
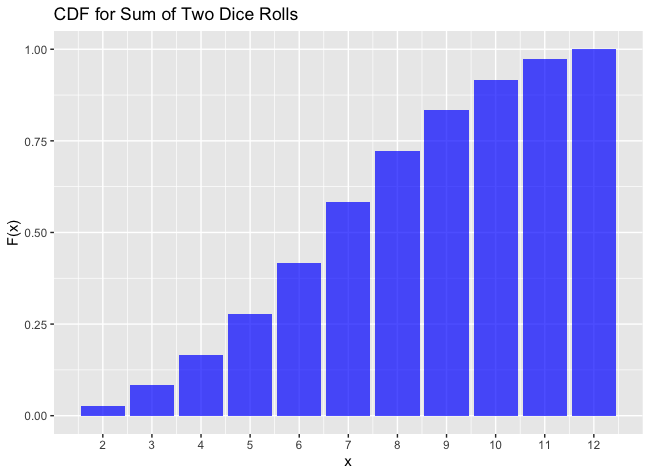 | 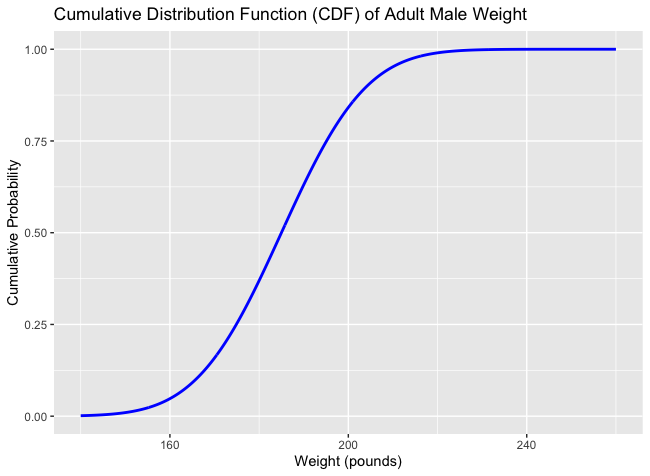 |
02.03 Multivariate Distributions
- Binomial Distribution
- Bernoulli Distribution
- Negative Binomial
- Multinomial Distribution
- Hypergeometric Distribution
| N = 20 | P = 0.5 |
|---|---|
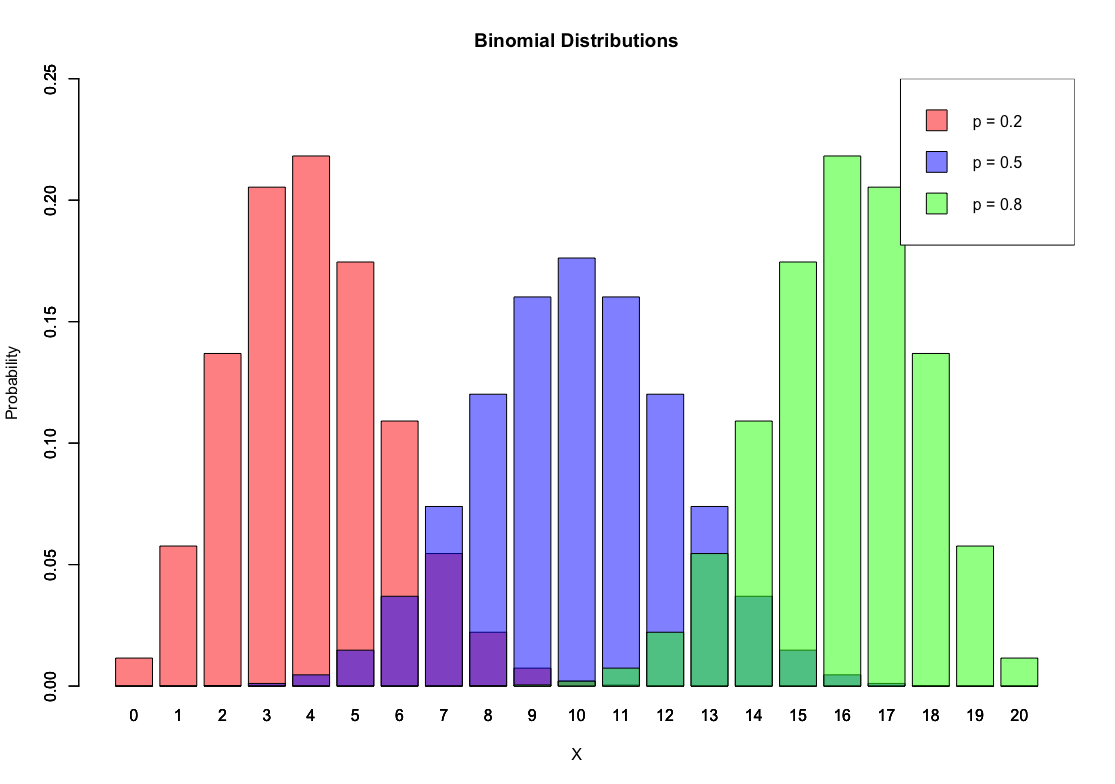 | 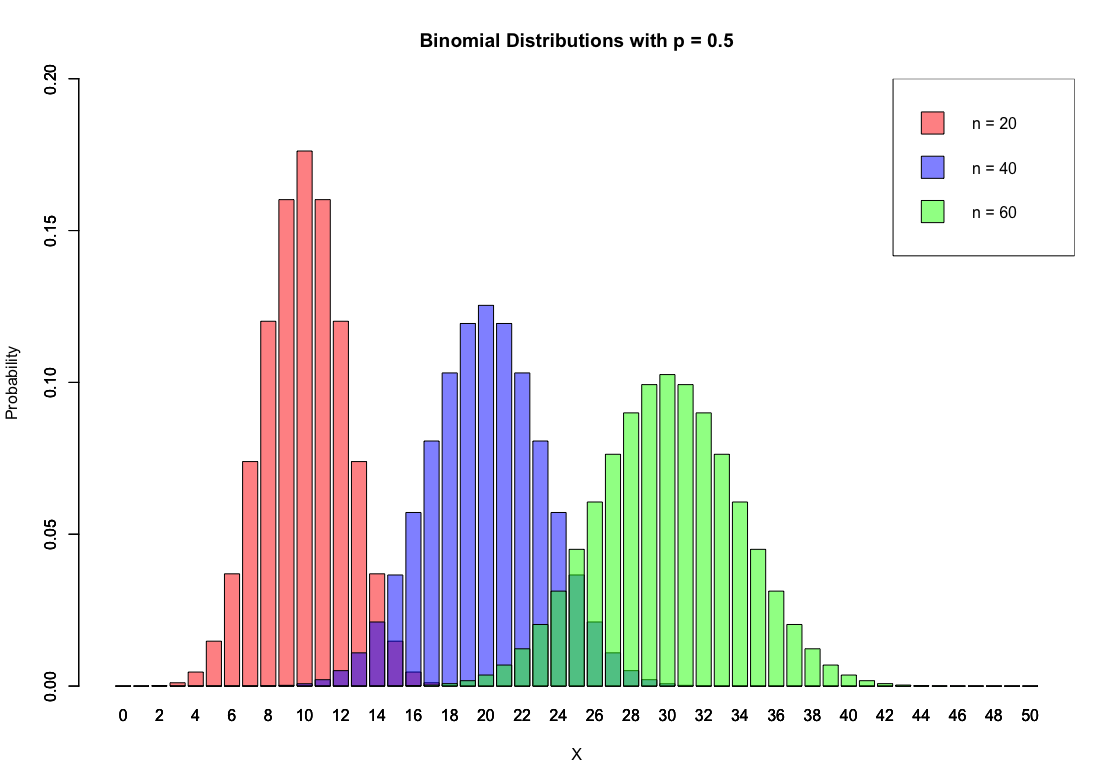 |
- Poisson Distribution
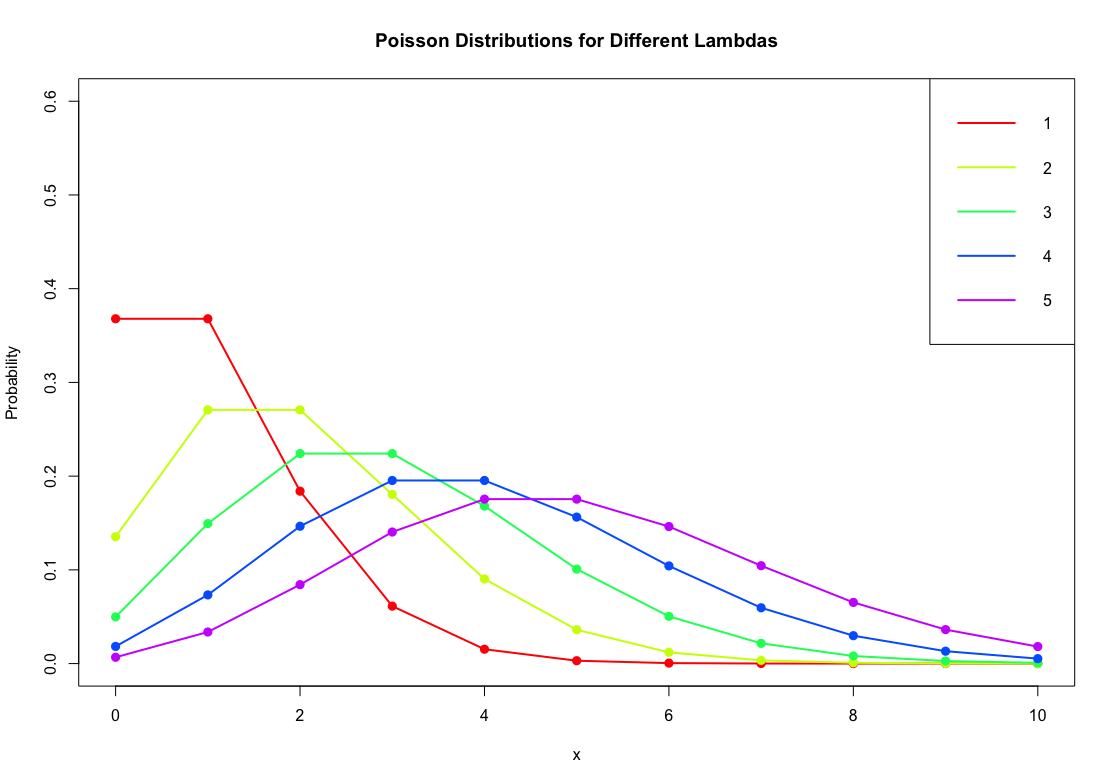
- Gamma Distribution
- X^2 Distribution
- Beta Distribution
- Exponential Distribution
- Normal Distribution
03 Statistical Inference
- Sampling, Statistics, Likelihood, Maximum Likelihood Estimator, Point Estimator
Other
Imagine this table, where
- is the total number of samples.
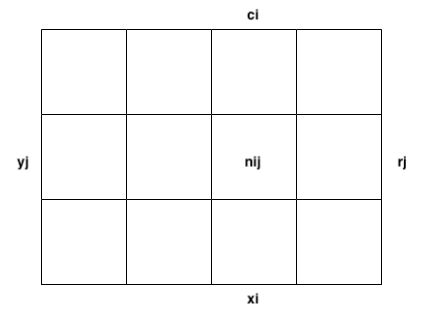
Joint probability refers to the likelihood of two events occurring together at the same point in time. It can be defined as
Marginal Probability refers to the probability irrespective of the outcome of another variable.
Conditional Distribution refers to the probability of of an event occurring, given that another event has occurred.
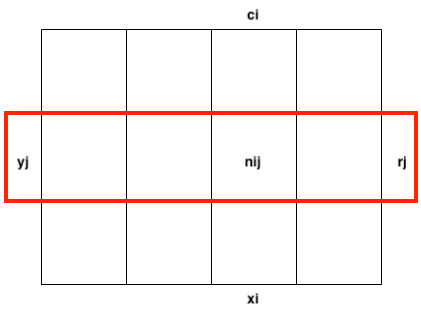 The same occurs for
The same occurs for
There are also two properties addition and multiplication In ,addition can give us the probability distribution of . Bayes Theorem can be derived from these previous rules. Let’s break down this formula.
- and are events
- is marginal probability (probability of evidence, under any circumstance)
- is the likelihood (probability of the evidence, given the belief is true)
- Is denoted as prior probability 先验概率
- is the posterior probability 后验概率
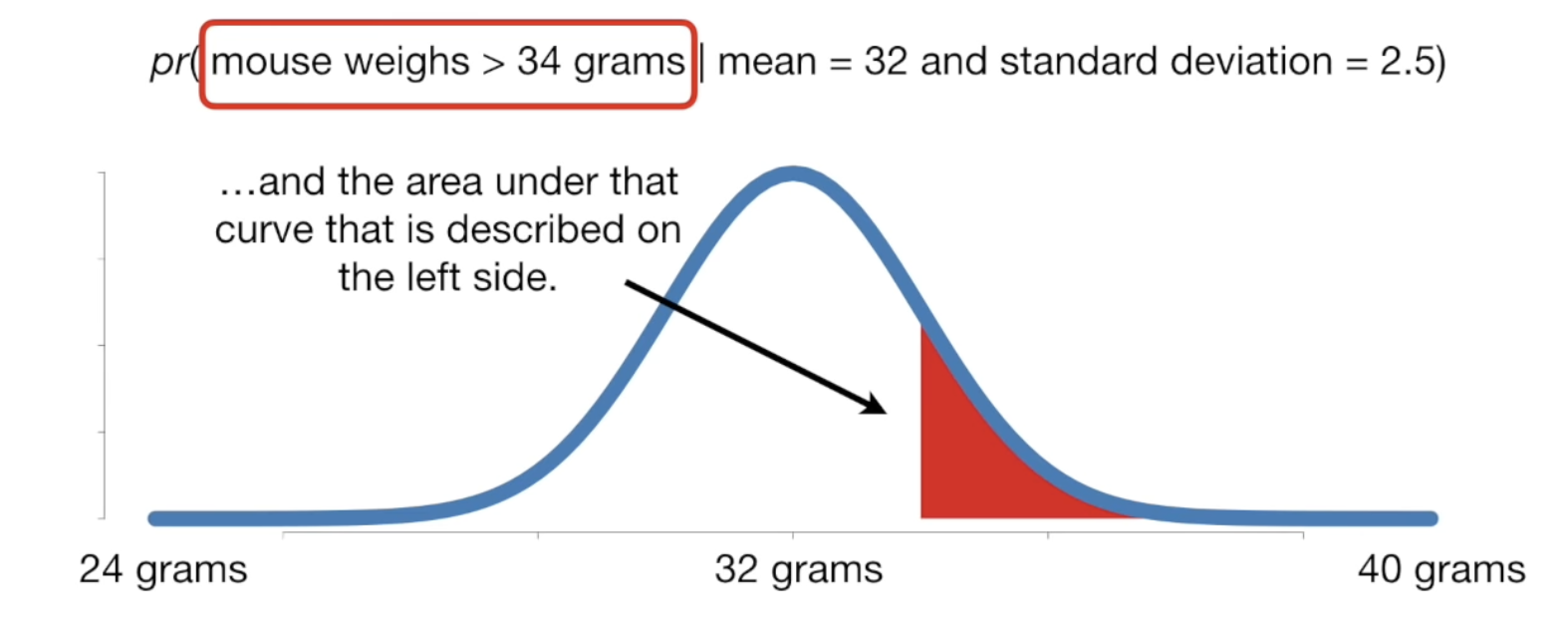
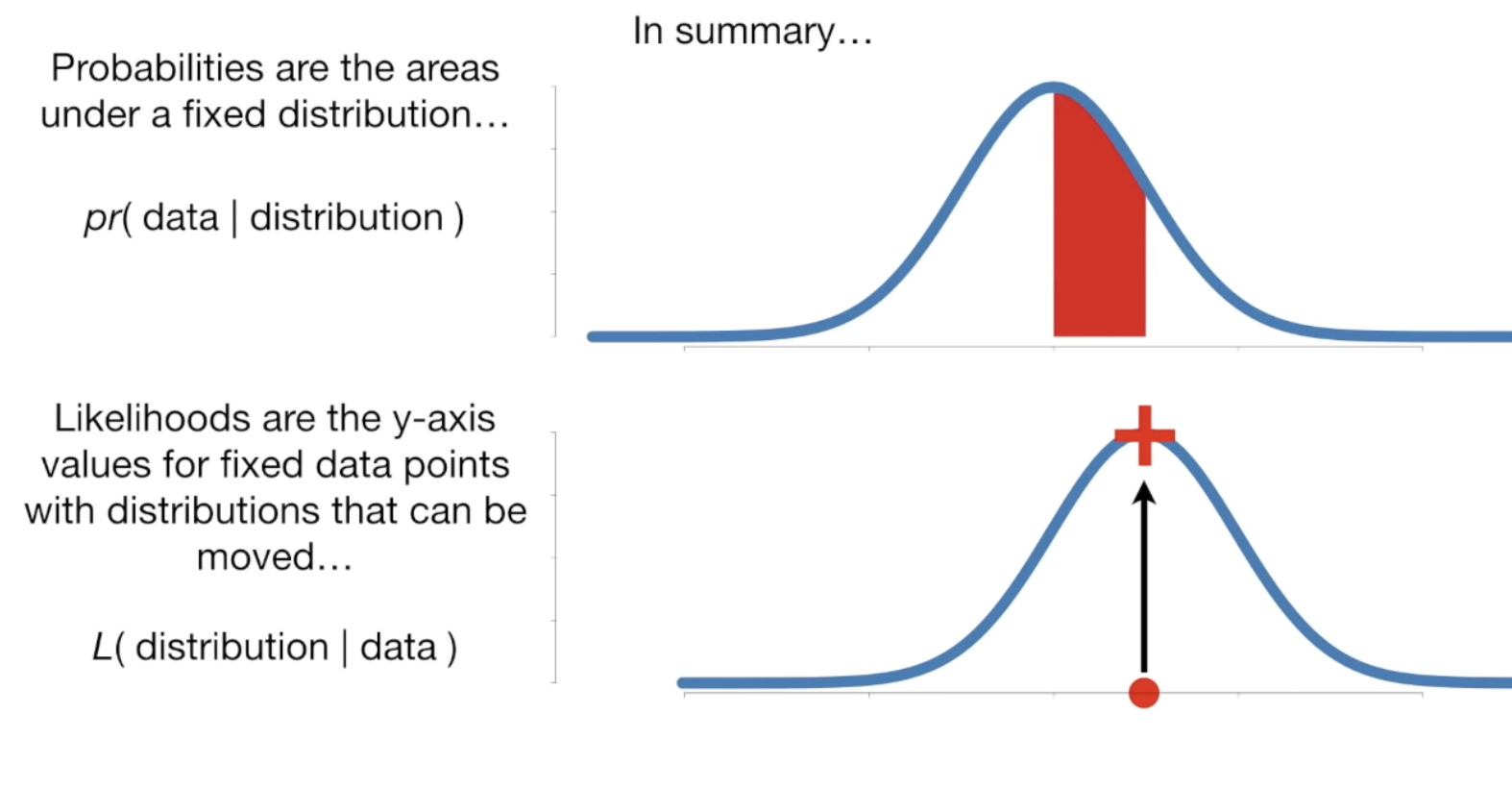
The difference between probability and likelihood
Probability: find the probability of a mouse weighing more than 34 given that the mean is 32 and standard deviation is 2.5
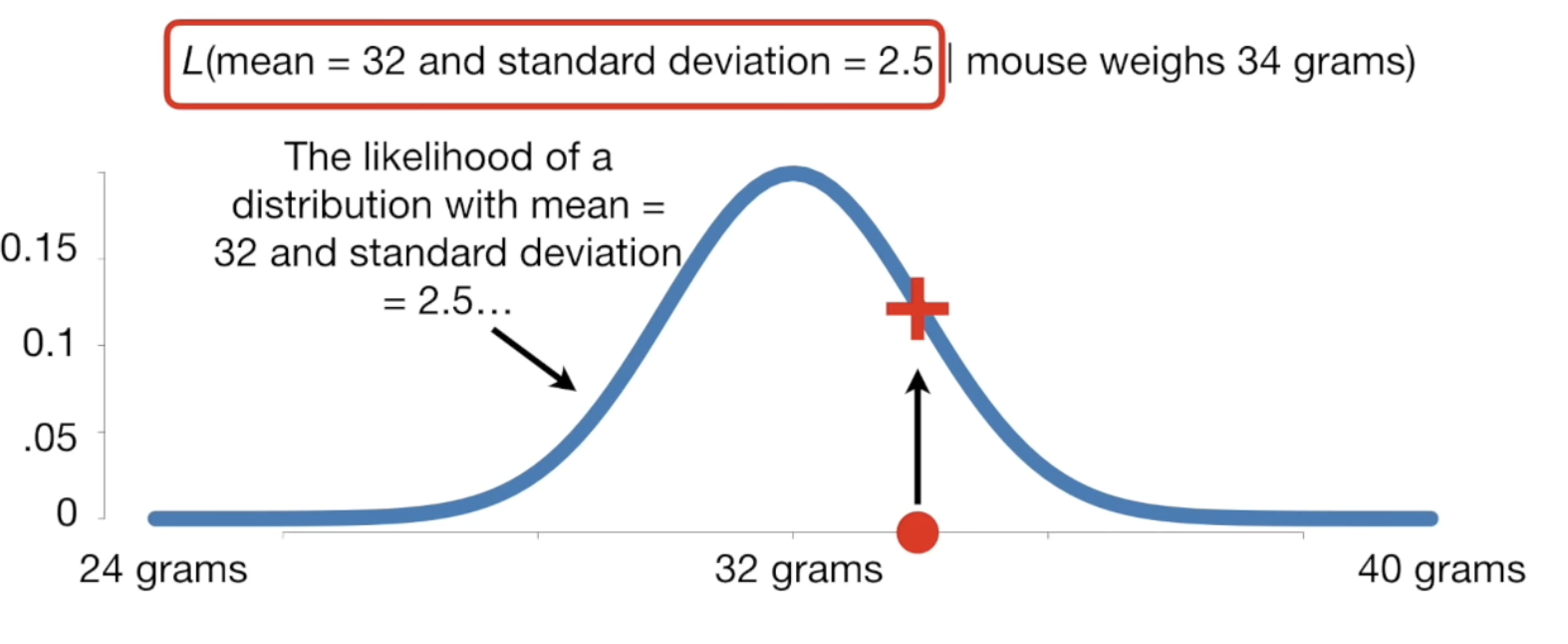
 Likelihood: find the probability of distribution where mean is 32 and standard deviation is 2.5 given that the mouse weighs 34
Likelihood: find the probability of distribution where mean is 32 and standard deviation is 2.5 given that the mouse weighs 34
 In summary
In summary
Let’s look at it in terms of Machine Learning models. Let be the data, and be a model.
Here are some read world examples.
A random variable has a probability distribution 分布概率 that represents the likelihood that any of the possible values would occur.
Probability Mass Function. For a discrete random variable that takes on a finite or countably infinite number of possible values, for all possible values of is known as the PMF. It is often denoted as
01.03 Distributions
02 Random Variables
In probability and statistics, a random variable is often used to model any probabilistic outcome. For example, we can ask, what is the probability that = 1 given. This is denoted as a probability density function (continuous)
A probability density (or probability density function, PDF). In the case of a continuous random variable, we have to find the probability that falls on some interval . P(a \leq X \leq b)= P(a < X \leq b)= P(a \leq X < b) = P(a < X < b) $$$$P(a < X <b) = \int_a^b f(x)dx where is the probability density function.
Cumulative density function or CDF. It can be defined as
 For example, the function is typically used to denote the CDF of a standard normal distribution.
For example, the function is typically used to denote the CDF of a standard normal distribution.
Expectation
Why the in prerequisite for expectation? https://www.stat.umn.edu/geyer/old06/5101/notes/n1.pdf
 Then what are some examples distribution whose expectation does not exist?
Then what are some examples distribution whose expectation does not exist?
Mathematical Expectation for discrete random variable is,
A continuous random variable can be represented as Variance The variance of a discrete random variable is denoted as Let and be two discrete random variables
Variance refers to the spread of a dataset. It is calculated as the average of the squared difference of each value in the distribution from the expected value.
Covariance
Correlation